Go에서 해시 테이블(Map)은 어떻게 구현되어 있을까?
요약
- Hash Table에서 해시 충돌(Hash Collision)에 대한 해결책으로 Open Addressing, Separate Chaining 등이 있다.
- Go에서는 Separate Chaining 방법으로 구현되어 있는데, 이 방법은 링크드 리스트와 같이 버킷의 엔트리에 엔트리를 붙이는 방법이다.
- 링크드 리스트나 트리의 구조로 chaining을 수행하는 다른 언어들과 달리 Go는 배열(Array)로 chaining을 수행한다.
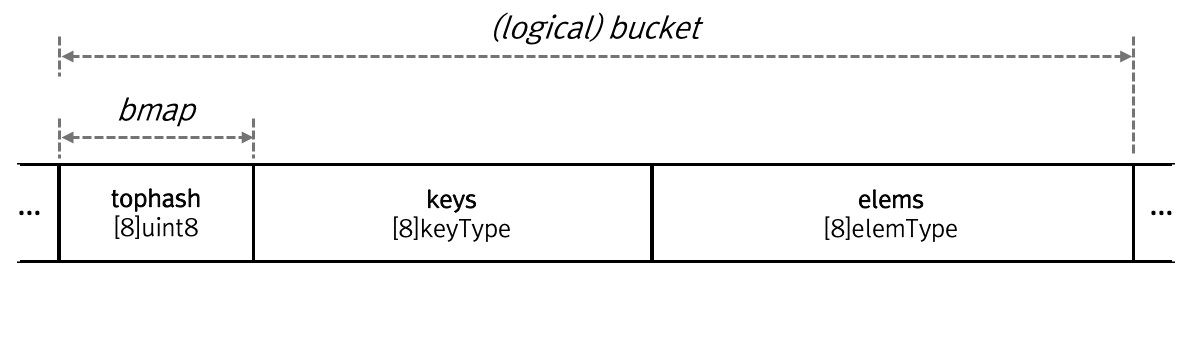
- 한 버킷에는 8개의 tophash 배열과 Key 배열, Value 배열이 존재한다.
- 한 버킷에 8개의 슬롯(slot)이 존재한다고 표현한다.
- tophash 배열에 각 Key의 해시 값의 최상위 8비트를 저장해둔다.
- 해시 충돌이 발생해 같은 버킷에 데이터를 저장할 경우, 그냥 비어있는 슬롯을 사용한다.
- 버킷은 메모리 상에 Key와 Value를 한 쌍으로 저장하지 않고, Key들을 먼저 할당하고 그 뒤에 Value들을 모아서 할당해둔다.
- 이는 메모리 정렬(memory alignment)의 효율을 얻기 위함이다.
- Go 해시 테이블의 Load Factor는 6.5로 설정되어 있다.
- 버킷 당 평균 Key-Value 슬롯 사용이 6.5개 이상이면 해시 테이블 사이즈를 두 배로 늘리는 growing 과정을 수행한다.
make(map[K]V, 100)과 같이 맵 생성 시 Key-Value의 개수에 대해 힌트를 주는 경우, 런타임은 다음 과정을 통해 버킷 개수를 설정한다.- 버킷 개수는 개
- Key-Value 데이터에 접근하기 위해서 다음과 같이 포인터 연산을 하여 Value를 찾는다.
이번 포스팅에서는 1.18 버전의 runtime/map.go 파일을 훑어보며 Go에서 해시 테이블이 어떻게 구현되어 있는지 살펴본다.
hmap,bmap,maptype이 어떻게 정의되어 있는지 살펴본다.- 맵을 생성하는
makemap()함수에 대해 살펴본다. - 키를 통해 맵에 접근하는
mapaccess()계열 함수에 대해 살펴본다.
1. hmap struct
Go 런타임에서는 맵 생성 시 hmap이라는 구조체의 포인터를 리턴하며, 이 hmap은 맵의 헤더라고 할 수 있다.
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}여기서 알고넘어가야 할 중요한 필드들은 다음과 같다.
B(uint8) : map이 가지는 버킷의 수에 를 취한 값.- map이 최대 개의 버킷을 가질 수 있도록 B값을 결정한다.
hash0(uint32) : 해시 충돌을 피하기 위한 랜덤 시드.buckets(unsafe.Pointer) : 실제 버킷들(array)을 가리키는 포인터.oldbuckets(unsafe.Pointer) : 버킷이 충분히 많이 차서 해시 충돌이 우려될 경우 버킷 개수를 늘려 재할당하는데, 이 과정(growing)이 진행될 때 이전 버킷 array를 가리킴. growing이 진행되지 않을 때는nil값을 가짐.nevacuate(uintptr) : growing이 진행 중에 oldbuckets에서 새로운 buckets로 버킷이 옮겨가게 되는데, 다음으로 옮겨갈 버킷에 대한 주소를 가리킴.extra(*mapextra) : 버킷의 수가 오버플로우되는 상황을 대비해서 미리 메모리 할당해둔 부분.
💡 (참고) uintptr vs unsafe.Pointer
- uintptr은 builtin.go의 주석에 따르면 어떤 포인터든 주소를 담을 수 있게 충분히 큰 integer 타입이라고 한다.
- unsafe.Pointer는 임의의 포인터 타입(
*ArbitraryType)을 표현하며, 실제 Go object를 가리키고 있다. C의*void처럼 어떤 타입의 포인터로든 변환할 수 있다. - unsafe.Pointer는 Go object를 가리키는 포인터로서 동작하고 있기 때문에 Go의 가비지 컬렉터에게 추적된다. 그러나 uintptr는 단순히 주소를 담는 정수형 변수기 때문에 가비지 컬렉션될 수 없으며, 사용하기에 매우 위험하다.
2. bmap struct
bmap은 Go 맵에서 버킷을 가리킨다.
type bmap struct {
tophash [bucketCnt]uint8
}
// bucketCnt는 8(1<<3)을 기본값으로 가진다.bucketCnt는 8을 기본값으로 가지며 한 버킷 당 저장할 수 있는 키-밸류 데이터 개수(슬롯 개수)를 뜻한다.
그리고 tophash는 이 버킷에 포함된 각 키의 해시 값에서 최상위 바이트(8비트), 즉 키의 해시값에서 왼쪽부터 8비트를 가지고 있는 배열이다.
이렇게 버킷 내의 키들에 대해 해시 값을 또 갖고 있는 이유는 Go에서의 해시테이블이 Separate Chaining 방식을 사용하는 다른 언어 구현체들과 다르게 버킷이 Linked List 기반이 아니고 그냥 Array이기 때문이다. 여기서 버킷이 실제 키-밸류 데이터를 담는 부분이라 bmap에 키 값과 밸류 값, 혹은 키와 밸류를 가리키는 포인터가 있을 것이라고 생각할 수 있다.
그러나 map.go 코드 상의 구현에는 bmap struct의 필드로 tophash만이 존재하며 키와 밸류는 존재하지 않는다.
그렇다면 키와 밸류는 어디에 저장되어 있을까?
실제로 bmap이 할당되는 과정이나 밸류를 갖고 오는 과정을 살펴보면 메모리 상에 다음과 같이 할당되어 있음을 알 수 있다.
type bmap struct {
tophash [8]uint8
}
keys [8]K
values [8]V코드 상에 keys와 values가 이렇게 나타나있지는 않지만 bmap이 할당된 메모리 이후에 실제로 8개의 키 함께 할당되어 있고 그 후에 8개의 밸류가 선형적으로 할당되어 있다.
여기서 < key0 | key1 | ... | key7 | val0 | val1 | ... | val7 > 이렇게 키끼리 밸류끼리 묶는 것보다, < key0 | val0 | ... | key7 | val7 > 과 같이 키와 밸류를 교대하며 할당하는 것이 더 편하지 않을까 하는 의문이 들 수 있다.
물론 키-밸류를 교대하며 각각을 한 쌍으로 할당하는 것이 데이터의 접근에 있어 코드가 덜 복잡하다.
그러나 map[int64]int8과 같은 타입의 경우 키-밸류를 페어로 할당하면 < 64비트 | 8비트 | 64비트 | 8비트 | ... > 와 같이 할당되는데, 메모리 정렬(memory alignment) 관점에서 봤을 때 8비트 후에 다량의 패딩이 추가되어 비효율이 발생할 수밖에 없다.
따라서 map[int64]int8을 Go의 구현대로 생성하면 < 64비트 | 64비트 | ... | 8비트 | 8비트 | ... >와 같은 형태로 할당되어 패딩을 제거할 수 있어 더 효율적이다.
우선 지금은 bmap에 대해서 이 정도로만 알아보고 추후에 mapaccess()나 mapassign() 함수를 설명할 때 자세히 살펴보도록 하겠다.
3. makemap() :: 맵 생성하기
m1 := make(map[k]v)
m2 := make(map[k]v, 1234)Go에서 맵은 위 코드를 통해 생성한다. m1처럼 생성할 수도 있지만, 이렇게 생성되는 초기 맵 사이즈에 비해 담아야 할 값들이 많다면 맵이 growing 과정을 여러번 거칠 수 있어 효율성이 떨어질 수 있다.
보다 나은 효율을 위해, m2처럼 값을 몇개를 담을건지 힌트(hint)를 주어 생성할 수 있다.
make(map[k]v, hint) 코드는 Go 런타임에서 makemap() 함수를 호출하게 한다.
makemap() 함수의 전체 코드는 다음과 같다.
// src/runtime/map.go
// makemap() 전체 코드
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
// initialize Hmap
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
// Find the size parameter B which will hold the requested # of elements.
// For hint < 0 overLoadFactor returns false since hint < bucketCnt.
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
// allocate initial hash table
// if B == 0, the buckets field is allocated lazily later (in mapassign)
// If hint is large zeroing this memory could take a while.
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}파라미터로 *maptype, int, *hmap이 들어가는데, maptype은 runtime/type.go에 다음과 같이 정의되어 있다.
type maptype struct {
typ _type
key *_type
elem *_type
bucket *_type // internal type representing a hash bucket
// function for hashing keys (ptr to key, seed) -> hash
hasher func(unsafe.Pointer, uintptr) uintptr
keysize uint8 // size of key slot
elemsize uint8 // size of elem slot
bucketsize uint16 // size of bucket
flags uint32
}3.1. makemap() - 필요 메모리 계산
// makemap() 부분 1
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
hint = 0
}
// ...makemap() 함수에서는 먼저 hint 값과 버킷의 사이즈를 기반으로 메모리가 얼마나 필요한지 계산한다.
이 때, overflow가 발생하거나 계산된 메모리 양이 maxAlloc보다 크다면 hint가 0으로 변경되고 나중에 B도 0으로 계산되며, 버킷은 추후에 lazily allocated된다.
(maxAlloc은 AMD64 시스템에서 bit로 32TiB에 해당한다.1)
3.2. makemap() - 해시 테이블 초기화
// makemap() 부분 2
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
// ...다음 부분에서 hmap을 할당하고, hash0 (해시 시드)를 설정한다.
(wyhash라는 알고리즘으로 랜덤 시드를 생성한다.)
3.3. makemap() - 할당할 버킷 수 계산
// makemap() 부분 3
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
// ...// overLoadFactor 함수는 같은 파일에 다음과 같이 구현되어 있다.
func overLoadFactor(count int, B uint bool) {
return count > bucketCnt &&
uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}주어진 hint값을 토대로 B값을 결정하는데, hint개의 키-밸류 데이터를 충분히 저장할 수 있는 버킷의 수를 구하게 된다.
map.go 파일을 보면 윗부분에 loadFactorNum, loadFactorDen 이라는 정수형 상수가 정의되어 있다.
기본으로 세팅된 값은 각각 13과 2로 loadFactorNum을 loadFactorDen으로 나누어 Load Factor를 결정한다.
Load Factor는 버킷 당 평균 키-밸류 데이터 개수를 뜻하며 Go에서는 이 값을 13/2 = 6.5로 사용한다.
결론적으로, 위 코드에서 가 되는 최소 B를 구하게 되고, 맵은 개의 버킷을 가질 수 있게 된다.
💡 (참고) Load Factor
- Load Factor가 버킷 당 평균 키-밸류 데이터 개수를 뜻하는데 현재 맵에 저장된 데이터가 Load Factor를 넘어가게 된다면 맵은 자동으로 용량을 늘리게 된다. (growing 과정)
- 만약 이 Load Factor가 너무 작다면 growing 과정이 자주 트리거되어 오버헤드가 발생하여 접근 시간이 낭비될 것이고, 너무 크다면 메모리 공간이 낭비될 것이다.
- 즉, Load Factor에 따라 시간과 공간이 trade-off 관계에 놓이게 되며, 이 값을 적당히 조정하는 것이 성능을 좌우한다고 할 수 있다.
- Java에서는 HashTable의 Load Factor로 75%를 사용한다.
추가) bucketShift(B) 함수는 를 리턴하고 B의 범위는 32bit 시스템에서 , 64bit 시스템에서 이다.
B의 정의가 버킷 개수에 를 취한 것이기 때문에 bucketShift(B) 함수의 역할은 주어진 B 값을 기반으로 가질 수 있는 버킷 개수를 계산하는 것이라고 할 수 있다.
3.4. makemap() - 버킷 Array 생성
// makemap() 부분 4
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h마지막 부분에서는 버킷 array를 생성하고 맵에 할당하는 과정이 포함되어 있다.
만약 위에서 B값이 0으로 정해진다면 여기서 버킷 array를 생성하지 않고, 값을 넣는 mapassign() 과정에서 버킷을 생성한다고 한다. (lazy allocate)
makemap() 함수에 파라미터로 받았던 t *maptype, 위에서 계산했던 B값을 makeBucketArray() 함수에 넣으면, 해당 함수에서 버킷 사이즈를 계산하여 메모리를 할당하고 반환해준다.
makeBucketArray() 함수에서 주목할 점은 버킷 개수가 충분히 클 때() 미리 overflow 버킷을 할당해둔다는 것이다.
또한 해당 함수에서 bmap의 사이즈를 계산해서 메모리를 할당하는데, bmap struct 구현에는 필드가 tophash [8]uint8만 있지만 실제로는 8개의 키와 8개의 밸류를 담을 공간까지 계산하여 메모리를 할당한다.
4. mapaccess() :: 맵에 접근하기
2016년 GopherCon에서 Keith Randall은 다음과 같이 설명했다. 2
Generic이 존재하는 다른 언어 같은 경우 맵에서 특정 키에 대한 값을 갖고오고자 할 때(lookup), v = m[k] 코드는 다음과 같이 컴파일 될 것이다.
// lookup
v = m[k]
// compiles to
v = runtime.lookup(m, k)
// where the runtime has the function
func<K, V> lookup(m map[K]V, k K) V그러나 Go에는 generic이 없으니 (1.18 이전) 위와 같은 개념과는 다르게 런타임을 구현해야했다. (Generic이 도입된 1.18에도 런타임에서 맵의 구현은 변경되지 않았다.)
런타임에서 generic 타입의 값을 가질 수 없으니 unsafe.Pointer를 사용해서 런타임에 키에 대한 정보를 얻을 수 있도록 구현했다.
// lookup
v = m[k]
// compiles to
pk := unsafe.Pointer(&k)
pv := runtime.lookup(typeOf(m), m, pk)
v = *(*V)pv
// where the runtime has the function
func lookup(t *mapType, m *mapHeader, k unsafe.Pointer) unsafe.Pointer특정 타입에 대해 따로 구현되어 있는 lookup 함수를 호출하는 대신, 단일로 존재하는 lookup 함수에 맵 타입, 헤더, 그리고 키에 대한 포인터를 파라미터로 입력함으로써 값에 대해 접근한다.
키가 어떤 타입인지 런타임에 알 수 있으므로 파라미터에 키(k)가 unsafe.Pointer로 설정되어 있다.
실제 map.go 파일에는 맵 접근 함수가 리턴 타입에 따라 여러 버전으로 구현되어 있다.
// elem에 대한 포인터를 반환
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
// key가 존재하는지에 대한 불린 값도 반환
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)
// key와 elem 모두 map iterator를 이용하여 반환
func mapaccessK(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, unsafe.Pointer)계획으로는 mapaccess1() 코드를 하나하나 살펴보려 했으나, 전문을 살펴보기에 코드가 조금 길어서 16년 GopherCon에서 발표한 자료[2]를 토대로 살펴보고자 한다.
해당 자료는 pseudo code 느낌이 나기는 하지만 실제 구현에서 중요한 부분을 충실하게 담고 있기 때문에 이해에는 큰 문제가 없을 것이라 생각한다.
lookup을 mapaccess로, mapHeader를 hmap으로, bucket을 bmap으로 바꿔서 봐도 무방하다.
// lookup looks up a key in a map and returns a pointer to the associated value.
// t = type of the map
// m = map
// key = pointer to key
func lookup(t* mapType, m *mapHeader, key unsafe.Pointer) unsafe.Pointer {
if m == nil || m.count == 0 {
return zero
}
hash := t.key.hash(key, m.seed) // hash := hashfn(key)
bucket := hash & (1 << m.log B-1) // bucket := hash % nbuckets
extra := byte(hash >> 56) // extra := top 8 bits of hash
b := (bucket) add(m.buckets, bucket*t.bucketsize)) // b := &m.buckets[bucket]
bucketloop:
for ; b != nil; b = b.overflow {
for i := 0; i < 8; i++ {
if b.extra[i] != extra { // check 8 extra hash bits
continue
}
k := add(b, dataOffset + i*t.keysize)
if t.key.equal(key, k) {
// return pointer to value_i
return add(b, dataOffset + 8*t.keysize + i*t.valuesize)
}
}
return zero
}
4.1. mapaccess() - 버킷 탐색
// mapaccess() 부분 1
hash := t.key.hash(key, m.seed) // hash := hashfn(key)
bucket := hash & (1 << m.log B-1) // bucket := hash % nbuckets
extra := byte(hash >> 56) // extra := top 8 bits of hash
b := (bucket) add(m.buckets, bucket*t.bucketsize)) // b := &m.buckets[bucket]
// ...먼저 조회하고자 하는 키의 해시값을 계산하고 버킷의 개수와 모듈러 연산(%)을 하여 키가 위치한 버킷을 구한다. (해싱할 때 hmap 생성 시 설정했던 hash0이라는 랜덤 시드를 사용한다.)
그리고 해시값의 최상위 8비트를 구하고 버킷의 주소를 가져온다.
여기서 add(p, x) 함수는 runtime/stubs.go 파일에 포인터(p)를 x만큼 다음 주소로 옮기라는 의미로 구현되어 있다.
4.2. mapaccess() - 키 탐색
// mapaccess() 부분 2
bucketloop:
for ; b != nil; b = b.overflow {
for i := 0; i < 8; i++ {
if b.extra[i] != extra { // check 8 extra hash bits
continue
}
k := add(b, dataOffset + i*t.keysize)
if t.key.equal(key, k) {
// return pointer to value_i
return add(b, dataOffset + 8*t.keysize + i*t.elemsize)
}
}
return zero여기 bucketloop는 버킷 내부에서 키를 탐색하는 과정이다.
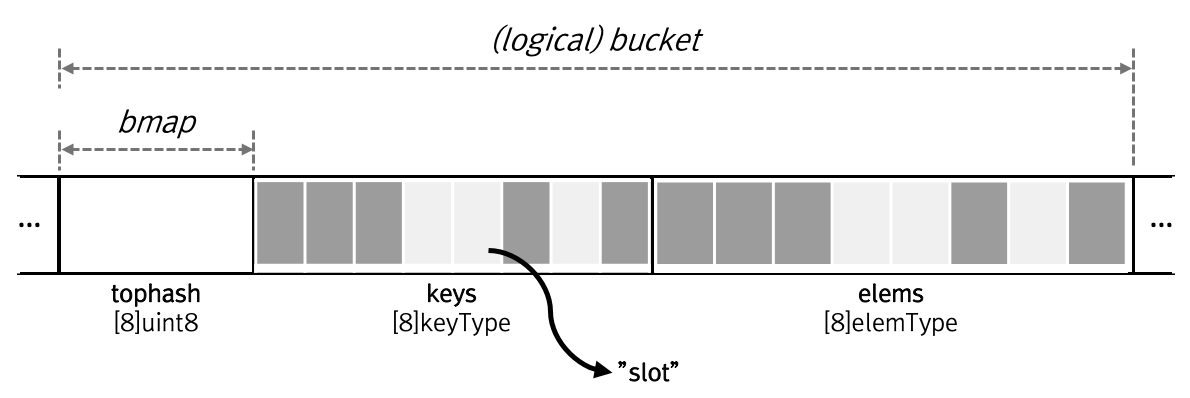
찾고자하는 키의 해시값의 최상위 8비트를 b.extra 배열(실제로는 tophash 배열)에서 탐색하는데, 버킷 내의 8개 슬롯에서 해당 키가 몇 번째 인덱스에 존재하는지 결과를 얻게 된다.
그리고 키가 존재하는지 한 번 더 확인 후 다음 과정을 통해 밸류(elem)에 접근하여 포인터를 반환한다.
dataOffset은 map.go 상단에 다음과 같이 상수로 정의되어 있다.
dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)이번 포스트의 1번 섹션에서 bmap에는 tophash만 구현되어 있고 키와 밸류에 대한 정보가 없다고 소개한 바 있다.
dataOffset이 bmap과 int64를 필드로 가지는 구조체에서 int64가 시작하는 위치의 오프셋을 가리키게 되므로, 키와 밸류에 대한 정보는 bmap 바깥에 저장된다는 것을 알 수 있다.
5. mapassign() :: 맵에 키 할당하기
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointermapassign() 함수는 인풋 파라미터와 리턴 값이 mapaccess1()과 같고 수행하는 기능 또한 유사하다.
다만 mapaccess1()이 현재 존재하는 키를 찾아 밸류를 포인터로 돌려줬다면, mapassign()은 키가 존재할 경우 밸류에 대한 포인터를 돌려주고 키가 존재하지 않을 경우 버킷에 슬롯을 할당하는 과정이 추가되어 있다.
또한 슬롯을 추가하기 전에 현재 맵이 Load Factor에 도달했거나 overflow 버킷이 너무 많을 경우 growing을 시작하는 과정을 포함한다.
이전에 bmap과 mapaccess 과정을 살펴볼 때 Go에서의 해시테이블은 Linked List가 아니라 버킷마다 8개의 슬롯을 가진 Array를 미리 할당하여 chaining을 구현한다고 소개했다.
따라서 새로운 키를 할당할 시, 해시 충돌이 발생하여 같은 버킷에 키가 할당될 경우 mapassign() 함수는 mapaccess()와 마찬가지로 버킷 내부 Array를 선형 탐색하다 빈 슬롯에 단순히 키를 할당하는 방법을 사용한다.
키를 할당하고 밸류가 들어갈 슬롯의 주소를 가리키는 포인터를 리턴하여 키를 할당하는 과정이 완료된다.
Java와 같이 링크드 리스트, 혹은 트리로 chaining이 구현되었다면 버킷에 키를 할당하는 과정이 보다 더 복잡했을 것이다.
그러나 Go는 포인터 연산과 비트 연산이 언어 차원에서 지원되므로, 미리 할당해둔 배열에 빈 공간(슬롯)을 찾아 값을 넣기만 하면 할당이 완료된다.
마무리
이번 포스팅에서는 Go의 해시 테이블 구현에 대해 코드 기반으로 살펴보았다.
글이 너무 길어져 growing 과정이나 맵 순회에 대해서는 다음 포스팅에서 다루고자 한다.
See Also
- golang/go :: src/runtime/map.go
- Hash Tables Implementation in Go
- Why Go cares about the difference between unsafe.Pointer and uintptr
- How the Go runtime implements maps efficiently (without generics)
Footnotes
-
golang/go :: src/runtime/malloc.go (accessed on 2022/04/06) ↩
-
Keith Randall, “Inside the Map Implementation”, GopherCon 2016. (slide) ↩